Annnnd sending 2 / 4 frames to video memory, stitched as a single transfer, to make them process and moved back as single transaction again?
I was also thinking that it's possible to need to have to apply more than one cube at a time (ex: technical, artistic, technical again) and it would be a pity to transfer and convert data more than once for the same frame(s).
Port Cube

Port Cube
That's the whole point of our CUDASynth proposal.
Stitching requires lots more GPU memory for minimal gain. It's not the overhead of memory transfer management that is the bottleneck. It's the data raw transfer time for large frames.
But I can certainly put CUDASynth into my filters, so that for example the following script has to transfer only one decoded frame on the PCIe, i.e., the final frame going back to the CPU.
DGSource(appropriate CUDASynth params) # only compressed data goes up to GPU, decoded frame is left on GPU
Cube(appropriate CUDASynth params) # uses frame on GPU, writes to GPU memory
Cube(appropriate CUDASynth params) # uses frame on GPU, writes to GPU memory
Cube(appropriate CUDASynth params) # uses frame on GPU, writes to CPU and returns it to Avisynth
Any CUDASynth enabled filter could be used in the chain. Any version of Avisynth or Vapoursynth could be used. Really guys, what's not to like?
Remember, I tried to interest developers in this years ago but no-one was interested. I even gave them a sample filter showing how to do it. Zero interest. Fine, I'll just do it for all my filters, and when people see how fast things can be maybe they will give it a thought.
OK, back to coding the DGCube() changes we've agreed on.
Stitching requires lots more GPU memory for minimal gain. It's not the overhead of memory transfer management that is the bottleneck. It's the data raw transfer time for large frames.
But I can certainly put CUDASynth into my filters, so that for example the following script has to transfer only one decoded frame on the PCIe, i.e., the final frame going back to the CPU.
DGSource(appropriate CUDASynth params) # only compressed data goes up to GPU, decoded frame is left on GPU
Cube(appropriate CUDASynth params) # uses frame on GPU, writes to GPU memory
Cube(appropriate CUDASynth params) # uses frame on GPU, writes to GPU memory
Cube(appropriate CUDASynth params) # uses frame on GPU, writes to CPU and returns it to Avisynth
Any CUDASynth enabled filter could be used in the chain. Any version of Avisynth or Vapoursynth could be used. Really guys, what's not to like?
Remember, I tried to interest developers in this years ago but no-one was interested. I even gave them a sample filter showing how to do it. Zero interest. Fine, I'll just do it for all my filters, and when people see how fast things can be maybe they will give it a thought.
OK, back to coding the DGCube() changes we've agreed on.
Port Cube
Avisynth+ CUDA stuff moved to a new thread. Please follow up there on that subject.
Also, I updated my last post above.
Also, I updated my last post above.
Port Cube
Got the new scheme coded and tested for RGBP16. Moving on to YUV420P16. Probably won't be done until tomorrow.
Port Cube
I'm thinking of not implementing full range input/output for YUV. You could still have a full or limited range LUT. For RGB, full range or limited would be allowed for input, lut, and output.
Will anyone pop an aneurysm if I do that? YUV from our disks, etc., is limited range.
Will anyone pop an aneurysm if I do that? YUV from our disks, etc., is limited range.
Port Cube
YUV from "usual disks" is limited TV range but YUV from some cameras (even pro ones like Arri) can be either limited or full.
While you have hands in it, do it the right way, or, at least, plan for future release.
Port Cube
t, this stuff is hard. Lots of equations rigorously derived from specs. That's why there is no existing solution.do it the right way
I'll plan for it and give an interim release without it. We need some samples for testing. Got any?
Port Cube
I have found a Canon Log3 file, YUV 4:2:2 full range:
https://krakenfiles.com/view/3hCxREqNdC/file.html
Sorry for the elephant size but I don't really know how to split it without doing damages.
You need to index with LWLibavVideoSource, as nVidia doesn't support 4:2:2 (yet).
Here is the cube, pay attention that it converts Log3 full to 709 full:
https://krakenfiles.com/view/xSAX60AqLZ/file.html
You can find more LUTs here https://tools.rodrigopolo.com/canonluts/
And a tool to play with them here https://cameramanben.github.io/LUTCalc/ ... index.html
Port Cube
That's the best you've got? OK, I'll try to work with it. 
Meanwhile, here is something to play with. Re-download DGCube.zip. It implements the new interface and should be good for everything except for full range YUV, which I am still working on. Refer to the document for details. Changes were extensive so your thorough testing will be greatly appreciated and amply rewarded.
Meanwhile, here is something to play with. Re-download DGCube.zip. It implements the new interface and should be good for everything except for full range YUV, which I am still working on. Refer to the document for details. Changes were extensive so your thorough testing will be greatly appreciated and amply rewarded.
Port Cube
Script error: the named argument "in" to DGCube had the wrong type.
DGCube("D:\Programmi\Media\AviSynth+\cube\1a_PQ1000_HLG_mode-nar_in-nar_out-nar_nocomp.cube", in=1, lut=0, out=1, interp="tetrahedral")
Why oh why.
P.S: It seems that we need to use "full" or "lim" (much better than 0 and 1). Please update txt.
DGCube("D:\Programmi\Media\AviSynth+\cube\1a_PQ1000_HLG_mode-nar_in-nar_out-nar_nocomp.cube", in=1, lut=0, out=1, interp="tetrahedral")
Why oh why.
P.S: It seems that we need to use "full" or "lim" (much better than 0 and 1). Please update txt.
Port Cube
Number of frames: 1792
Length (hh:mm:ss.ms): 00:01:14.741
Frame width: 3840
Frame height: 2064
Framerate: 23.976 (24000/1001)
Colorspace: YUV420P10
z_ConvertFormat(pixel_type="RGBP16", colorspace_op="2020:st2084:2020:limited=>rgb:st2084:2020:full", resample_filter_uv="spline64", dither_type="error_diffusion")
DGCube("D:\Programmi\Media\AviSynth+\cube\1a_PQ1000_HLG_mode-nar_in-nar_out-nar_nocomp.cube", in="full", lut="full", out="full")
z_ConvertFormat(pixel_type="YUV420P10", colorspace_op="rgb:std-b67:2020:full=>2020:std-b67:2020:limited", resample_filter_uv="spline64", dither_type="error_diffusion")
Frames processed: 1792 (0 - 1791)
FPS (min | max | average): 1.389 | 6.633 | 5.533
Process memory usage (max): 614 MiB
Thread count: 14
CPU usage (average): 8.4%
GPU usage (average): 16%
VPU usage (average): 10%
GPU memory usage: 1886 MiB
GPU Power Consumption (average): 42.5 W
Time (elapsed): 00:05:23.864
DGCube("D:\Programmi\Media\AviSynth+\cube\1a_PQ1000_HLG_mode-nar_in-nar_out-nar_nocomp.cube", in="lim", lut="full", out="lim")
Frames processed: 1792 (0 - 1791)
FPS (min | max | average): 2.799 | 57.32 | 27.42
Process memory usage (max): 543 MiB
Thread count: 12
CPU usage (average): 8.4%
GPU usage (average): 56%
VPU usage (average): 42%
GPU memory usage: 1826 MiB
GPU Power Consumption (average): 54.5 W
Time (elapsed): 00:01:05.359
Length (hh:mm:ss.ms): 00:01:14.741
Frame width: 3840
Frame height: 2064
Framerate: 23.976 (24000/1001)
Colorspace: YUV420P10
z_ConvertFormat(pixel_type="RGBP16", colorspace_op="2020:st2084:2020:limited=>rgb:st2084:2020:full", resample_filter_uv="spline64", dither_type="error_diffusion")
DGCube("D:\Programmi\Media\AviSynth+\cube\1a_PQ1000_HLG_mode-nar_in-nar_out-nar_nocomp.cube", in="full", lut="full", out="full")
z_ConvertFormat(pixel_type="YUV420P10", colorspace_op="rgb:std-b67:2020:full=>2020:std-b67:2020:limited", resample_filter_uv="spline64", dither_type="error_diffusion")
Frames processed: 1792 (0 - 1791)
FPS (min | max | average): 1.389 | 6.633 | 5.533
Process memory usage (max): 614 MiB
Thread count: 14
CPU usage (average): 8.4%
GPU usage (average): 16%
VPU usage (average): 10%
GPU memory usage: 1886 MiB
GPU Power Consumption (average): 42.5 W
Time (elapsed): 00:05:23.864
DGCube("D:\Programmi\Media\AviSynth+\cube\1a_PQ1000_HLG_mode-nar_in-nar_out-nar_nocomp.cube", in="lim", lut="full", out="lim")
Frames processed: 1792 (0 - 1791)
FPS (min | max | average): 2.799 | 57.32 | 27.42
Process memory usage (max): 543 MiB
Thread count: 12
CPU usage (average): 8.4%
GPU usage (average): 56%
VPU usage (average): 42%
GPU memory usage: 1826 MiB
GPU Power Consumption (average): 54.5 W
Time (elapsed): 00:01:05.359
Port Cube
Thank you for testing. Looks good so far.
Congrats on guessing new syntax. Never underestimate the t!
Text document was updated.
Congrats on guessing new syntax. Never underestimate the t!
Text document was updated.
Port Cube
I see tiny discrepancies between the product of external (identical to AVSCube) and of internal processing (look at graphs, mostly).
z_ConvertFormat(pixel_type="RGBP16", colorspace_op="2020:st2084:2020:limited=>rgb:st2084:2020:full", resample_filter_uv="spline64", dither_type="error_diffusion")
Cube("D:\Programmi\Media\AviSynth+\cube\1a_PQ1000_HLG_mode-nar_in-nar_out-nar_nocomp.cube", fullrange=true)
z_ConvertFormat(pixel_type="YUV420P10", colorspace_op="rgb:std-b67:2020:full=>2020:std-b67:2020:limited", resample_filter_uv="spline64", dither_type="error_diffusion")
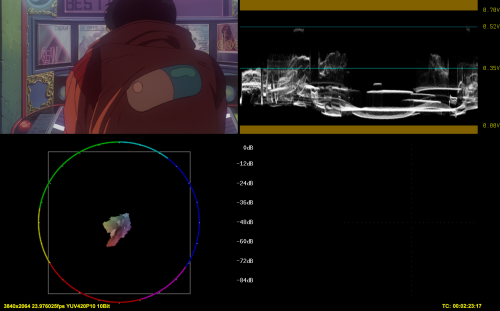
z_ConvertFormat(pixel_type="RGBP16", colorspace_op="2020:st2084:2020:limited=>rgb:st2084:2020:full", resample_filter_uv="spline64", dither_type="error_diffusion")
DGCube("D:\Programmi\Media\AviSynth+\cube\1a_PQ1000_HLG_mode-nar_in-nar_out-nar_nocomp.cube", in="full", lut="full", out="full")
z_ConvertFormat(pixel_type="YUV420P10", colorspace_op="rgb:std-b67:2020:full=>2020:std-b67:2020:limited", resample_filter_uv="spline64", dither_type="error_diffusion")
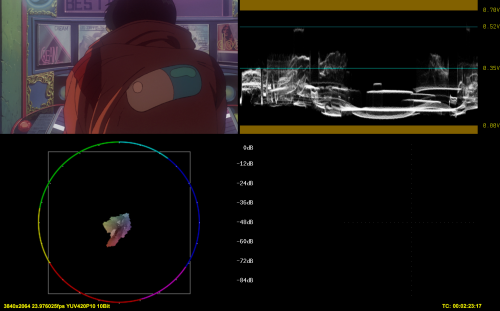
DGCube("D:\Programmi\Media\AviSynth+\cube\1a_PQ1000_HLG_mode-nar_in-nar_out-nar_nocomp.cube", in="lim", lut="full", out="lim")
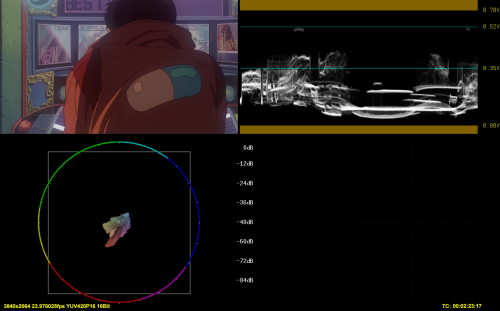
In limited LUT, the result on internal processing is totally wrong:
z_ConvertFormat(pixel_type="RGBP16", colorspace_op="2020:st2084:2020:limited=>rgb:st2084:2020:limited", resample_filter_uv="spline64", dither_type="error_diffusion")
Cube("D:\Programmi\Media\AviSynth+\cube\WarnerBros_PQToHLG_MaxCLL_1000.cube", fullrange=true)
z_ConvertFormat(pixel_type="YUV420P10", colorspace_op="rgb:std-b67:2020:limited=>2020:std-b67:2020:limited", resample_filter_uv="spline64", dither_type="error_diffusion")
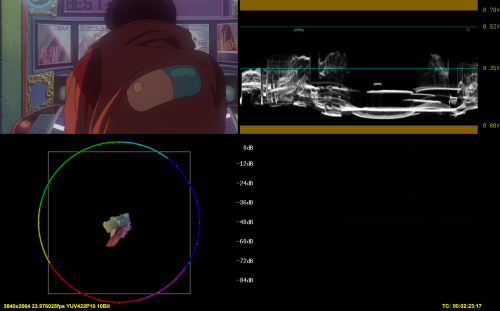
z_ConvertFormat(pixel_type="RGBP16", colorspace_op="2020:st2084:2020:limited=>rgb:st2084:2020:limited", resample_filter_uv="spline64", dither_type="error_diffusion")
DGCube("D:\Programmi\Media\AviSynth+\cube\WarnerBros_PQToHLG_MaxCLL_1000.cube", in="lim", lut="lim", out="lim")
z_ConvertFormat(pixel_type="YUV420P10", colorspace_op="rgb:std-b67:2020:limited=>2020:std-b67:2020:limited", resample_filter_uv="spline64", dither_type="error_diffusion")
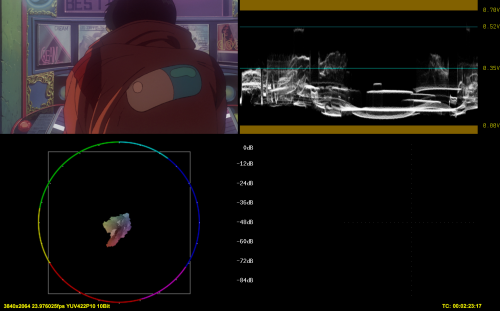
DGCube("D:\Programmi\Media\AviSynth+\cube\WarnerBros_PQToHLG_MaxCLL_1000.cube", in="lim", lut="lim", out="lim")
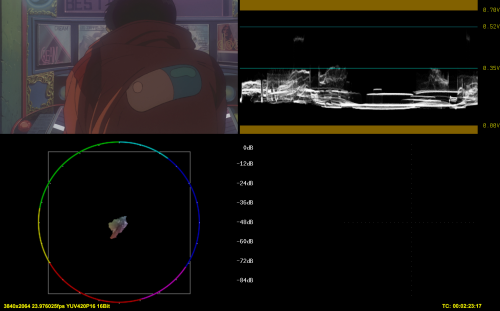
Port Cube
Let's look at that after we fix your big issue.
Confirmed. I have it fixed for CPU code. Just have to port it to GPU and do some regression testing, and then I can give you a new test version.In limited LUT, the result on internal processing is totally wrong
Port Cube
Please re-download and test. Should be working for lim-lim-lim YUV. If you confirm it is working we can look at the tiny discrepancies.
Port Cube
Yes, it works now.
1) BBC PQ to HLG, external conversion
z_ConvertFormat(pixel_type="RGBP16", colorspace_op="2020:st2084:2020:limited=>rgb:st2084:2020:full", resample_filter_uv="spline64", dither_type="error_diffusion")
DGCube("D:\Programmi\Media\AviSynth+\cube\1a_PQ1000_HLG_mode-nar_in-nar_out-nar_nocomp.cube", in="full", lut="full", out="full")
z_ConvertFormat(pixel_type="YUV420P10", colorspace_op="rgb:std-b67:2020:full=>2020:std-b67:2020:limited", resample_filter_uv="spline64", dither_type="error_diffusion")
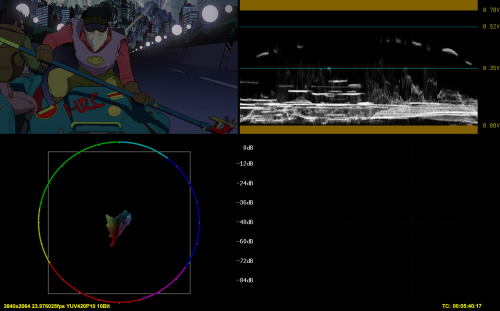
2) BBC PQ to HLG, internal conversion
DGCube("D:\Programmi\Media\AviSynth+\cube\1a_PQ1000_HLG_mode-nar_in-nar_out-nar_nocomp.cube", in="lim", lut="full", out="lim")
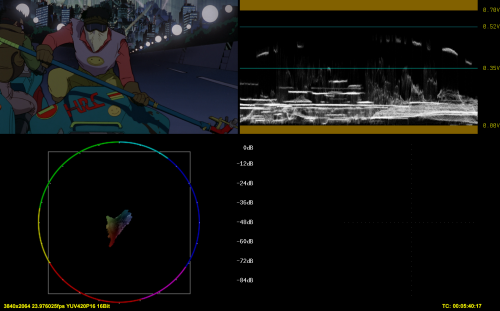
3) Warner PQ to HLG, external conversion
z_ConvertFormat(pixel_type="RGBP16", colorspace_op="2020:st2084:2020:limited=>rgb:st2084:2020:limited", resample_filter_uv="spline64", dither_type="error_diffusion")
DGCube("D:\Programmi\Media\AviSynth+\cube\WarnerBros_PQToHLG_MaxCLL_1000.cube", in="lim", lut="lim", out="lim")
z_ConvertFormat(pixel_type="YUV420P10", colorspace_op="rgb:std-b67:2020:limited=>2020:std-b67:2020:limited", resample_filter_uv="spline64", dither_type="error_diffusion")
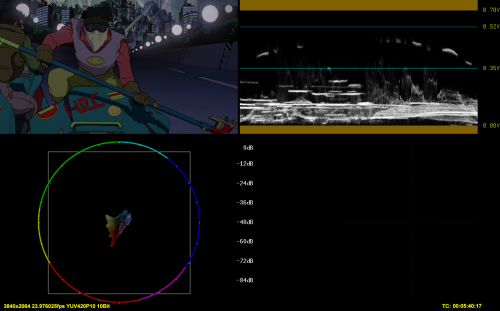
4) Warner PQ to HLG, internal conversion
DGCube("D:\Programmi\Media\AviSynth+\cube\WarnerBros_PQToHLG_MaxCLL_1000.cube", in="lim", lut="lim", out="lim")
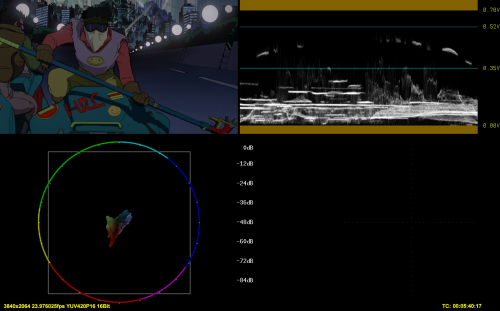
1) and 3) are identical to my eyes and according to graphs
2) and 4) are identical to my eyes and according to graphs
1) and 2), such as 3) and 4) have some discrepancies, both in luma and color (look at the area around the smiley)
4k frames (same order):




Port Cube
Good, thank you.
When you post new stream results, I' need to get the source stream in order to directly compare to your results. So can I get that stream please?
When you post new stream results, I' need to get the source stream in order to directly compare to your results. So can I get that stream please?
Port Cube
Mmm... hard to decide what piece to send. There are some parts that show the difference better and they are all really far from each other.
The m2ts is 96.062.312.448 bytes.
Here is a piece with broad enough luma and chroma ranges.
https://krakenfiles.com/view/mABFkMxsgb/file.html
Port Cube
Thank you.
Regarding 1-2 comparison. I guess it's because you use STD B67 for output. I don't do any conversions like that. You did that because you think it's appropriate for HLG? DGCube doesn't know what kind of LUT you are using. As I mentioned before, unless I implement the whole of z to accommodate any conversion you want, there will be discrepancies. I'm not excited about doing that so unless there is a middle ground, maybe best to just drop internal conversion.
There's also your dithering, which I do not do.
Anyway, let me investigate some more.
Regarding 1-2 comparison. I guess it's because you use STD B67 for output. I don't do any conversions like that. You did that because you think it's appropriate for HLG? DGCube doesn't know what kind of LUT you are using. As I mentioned before, unless I implement the whole of z to accommodate any conversion you want, there will be discrepancies. I'm not excited about doing that so unless there is a middle ground, maybe best to just drop internal conversion.
There's also your dithering, which I do not do.
Anyway, let me investigate some more.
